Come funzione l'intelligenza artificiale: analisi di ChatGPT per capire come nascono le risposte ai nostri quesiti
Come riesce ChatGPT a rispondere con coerenza e naturalezza a qualsiasi domanda? Il processo è più articolato di quanto sembri: inizia con l’analisi del testo dell’utente, prosegue con l’elaborazione tramite rete neurale Transformer, quindi genera, rifinisce e controlla la risposta prima di consegnarla. Un viaggio invisibile che unisce linguaggio, matematica e intelligenza artificiale.
Come ChatGPT elabora una domanda e produce una risposta
ChatGPT è un modello di intelligenza artificiale basato sull’architettura dei “transformer”, progettato per comprendere e generare testi in modo simile al linguaggio umano.
Ma cosa succede, esattamente, quando un utente pone una domanda e ChatGPT elabora la risposta? In questo articolo esaminiamo i passaggi fondamentali che consentono a ChatGPT di interpretare un quesito e fornire una risposta coerente.
Prima in sintesi poi in dettaglio fase per fase. Tutto scritto ovviamente grazie a ... ChatGPT.
Come funziona ChatGPT in pillole
1. Acquisizione e tokenizzazione dell’input
Inserimento della domanda
L’utente scrive la propria domanda, che può assumere molteplici forme: frasi compiute, parole chiave o comandi espliciti.
Tokenizzazione
Prima che il testo possa essere elaborato, viene convertito in una serie di “token”. I token sono piccole porzioni di testo (possono essere singole parole, frammenti di parole o simboli) che il modello può comprendere.
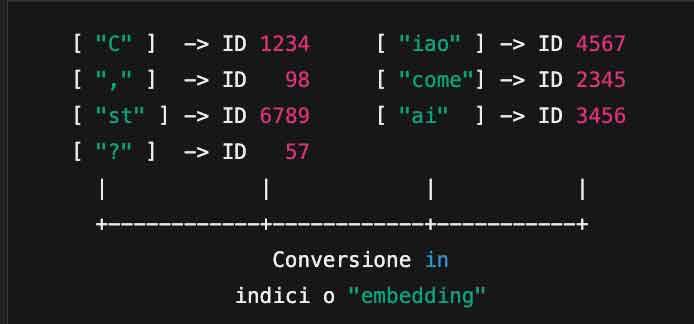
Ad esempio, la frase “Ciao, come stai?” potrebbe essere divisa in token come “C”, “iao”, “,”, “come”, “st”, “ai”, “?”.
Rappresentazione numerica
Ogni token viene mappato in una rappresentazione numerica (nello specifico, un indice all’interno di un vocabolario molto vasto). Così, invece del testo “Ciao, come stai?”, ChatGPT lavora con una sequenza di numeri.
2. Elaborazione attraverso l’architettura transformer
Una volta ottenuta la sequenza di token in forma numerica, il modello la elabora secondo l’architettura “transformer”, composta di due componenti fondamentali: gli encoder (per i modelli che ne fanno uso) e i decoder. ChatGPT, nella sua versione attuale, utilizza in larga parte blocchi di decoder autoregressivi per generare il testo.
Attenzione (Attention Mechanism)
Self-Attention: ChatGPT esamina i token della frase, verificando come ciascun token si relaziona con gli altri per cogliere contesto, significato e relazioni sintattiche.
Mascheramento (Masking): Per la generazione predittiva, il modello “nasconde” i token futuri, in modo da produrre le parole in ordine sequenziale, prevedendo un token alla volta.
Rappresentazione del contesto
Positional Embeddings: Poiché il modello riceve i token come una lista, ha bisogno di sapere in quale posizione di questa sequenza si trovi ogni token. I positional embeddings forniscono al modello questa consapevolezza della posizione.
Pesi appresi (Parametri): Durante l’addestramento, il modello ha appreso milioni (o addirittura miliardi) di pesi che codificano le regole del linguaggio, la semantica e la struttura della frase.
3. Generazione della risposta
3.1. Predizione dei token successivi
ChatGPT utilizza una tecnica di generazione detta autogressione. Ciò significa che:
Si concentra sui token che ha già “letto” (ovvero l’input e i token già generati).
Predice il token più probabile successivo.
Aggiunge il token scelto alla sequenza in uscita.
Ripete il processo finché non raggiunge una lunghezza massima o finché non “ritiene” di aver completato la risposta.
Questo processo è simile a come un essere umano può completare una frase parola dopo parola, tenendo conto del contesto già stabilito.
3.2. Gestione della coerenza
Temperature e Top-k/Top-p sampling: Per controllare la variabilità e la creatività della risposta, possono essere regolati alcuni parametri:
Temperature: Più è alto, più la scelta dei token successivi è “creativa”, mentre più è basso, più la generazione è “conservativa” e focalizzata sulle opzioni più probabili.
Top-k e Top-p: Limitano le scelte successive a un sottoinsieme dei token più probabili, riducendo il rischio di parole fuori contesto o troppo insolite.
4. Rifinitura con istruzioni e contesto
ChatGPT, oltre alla pura generazione sequenziale, è allenato per seguire istruzioni (Instruction Tuning). Ciò significa che:
Osserva la richiesta dell’utente, analizzando la forma e il contenuto della domanda.
Identifica l’obiettivo: rispondere a una domanda, fare un riassunto, tradurre, fornire suggerimenti, ecc.
Applica regole e linee guida: Per evitare risposte fuorvianti o inappropriate, ChatGPT integra linee guida etiche e limiti imposti durante la fase di addestramento.
In aggiunta, se disponibile, ChatGPT usa i cosiddetti prompt ingegnerizzati (prompt engineering) che possono fornire contesto extra e istruzioni su come formattare o modulare la risposta.
5. Controllo qualità e finalizzazione
Prima di presentare la risposta all’utente:
Verifica di consistenza: Il testo generato dovrebbe rispettare la coerenza con la domanda e non contraddirsi nel corso della generazione.
Approvazione finale: Se il modello rileva che la risposta può essere inappropriata o non conforme alle politiche di contenuto, filtra o modifica parti della risposta.
6. Rilascio della risposta all’utente
Una volta ultimate tutte le fasi:
Il testo generato viene inviato come output.
Richiesta di feedback (implicito): ChatGPT non impara direttamente dalla conversazione in corso (per ragioni di privacy e sicurezza), ma se ci sono aggiornamenti o sessioni di addestramento future, i miglioramenti possono riflettersi nelle versioni successive del modello.
Conclusioni
Il processo di elaborazione di ChatGPT è un viaggio complesso che combina:
Comprensione del linguaggio (tokenizzazione, embeddings, attenzione),
Modellazione contestuale (architettura transformer con meccanismi di self-attention),
Generazione sequenziale autoregressiva (token dopo token con controllo di coerenza),
Applicazione di linee guida e filtri (per garantire risposte adeguate).
Sebbene ChatGPT non “pensi” come un essere umano, sfrutta una rete neurale addestrata su enormi quantità di testi per identificare pattern e generare risposte di senso compiuto. Attraverso l’architettura transformer, è in grado di cogliere le sfumature del linguaggio e proporre risposte naturali, precise e coerenti con il contesto della domanda.
Come funziona ChatGPT: passaggio per passaggio
Capitolo 1: l’analisi del testo di Input
Quando un utente invia una domanda o un comando a ChatGPT, la prima operazione fondamentale consiste nell’analisi del testo di input.
Questo stadio iniziale è ovviamente un passaggio fondamentale perché pone le basi per l’intera catena di elaborazione successiva.
Vediamo, passo dopo passo, quali sono i principali elementi di questa fase.
1. Acquisizione del testo
Il processo comincia con la ricezione del contenuto: tutto ciò che l’utente ha digitato (frasi, parole chiave, comandi) viene catturato dal sistema. Non importa se il messaggio è lungo, breve, formale, informale o include segni di punteggiatura particolari: l’obiettivo è di assorbire integralmente il contenuto senza perdere dettagli.
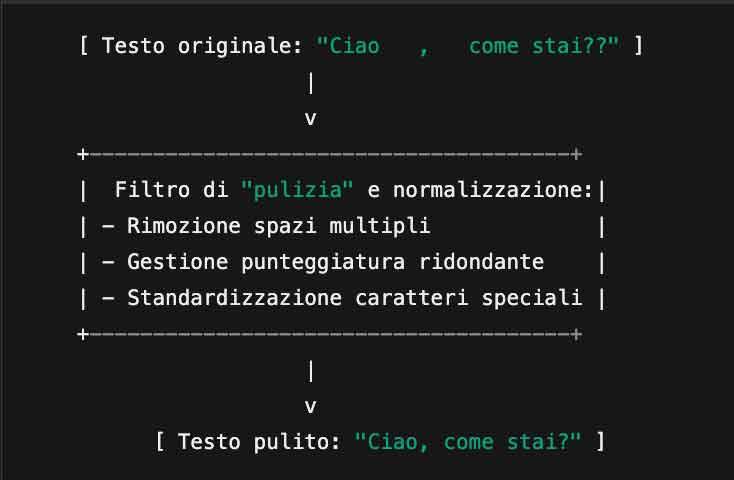
2. Pre-elaborazione (Pulizia e Normalizzazione)
Dopo l’acquisizione, il testo viene sottoposto a una prima “pulizia” logica, finalizzata a rendere più agevole l’interpretazione successiva:
Rimozione di elementi superflui: Spazi multipli, segni di punteggiatura ridondanti o simboli non riconosciuti vengono gestiti o convertiti in una forma standard.
Uniformazione di caratteri speciali: Lettere accentate o segni particolari vengono normalizzati (se necessario e se previsto dalle regole di preprocessing), in modo che il modello possa riconoscerli correttamente.
Esempio: Se il testo contiene “Caffè,” verrà mantenuto come tale, ma se si trattasse di un simbolo non previsto dalla codifica, questo verrebbe mappato in un formato compatibile.
3. Tokenizzazione
Una volta terminata la prima pulizia, il passo successivo è la tokenizzazione, ossia la suddivisione del testo in singole unità chiamate token.
Definizione di token: Un token può essere una parola intera, una parte di parola, un segno di punteggiatura o un simbolo specifico.
Esempio di tokenizzazione:
Testo originale: “Ciao, come stai?”
Possibile suddivisione in token: [“C”, “iao”, “,”, “come”, “st”, “ai”, “?”]
La tokenizzazione è fortemente influenzata dal vocabolario del modello, una mappa che associa a ogni token un indice numerico. In questo modo, la frase iniziale viene trasformata in una sequenza di numeri che la rappresentano in maniera univoca.
4. Mapping in rappresentazioni numeriche
Dopo aver creato l’elenco di token, ciascuno di essi viene convertito in un indice (un numero intero) o in un embedding (un vettore di numeri in uno spazio multidimensionale).
Indice: È l’ID del token all’interno di un dizionario interno, immenso, che ChatGPT ha “appreso” durante l’addestramento.
Embedding: Una rappresentazione densa che codifica non solo l’identità del token, ma anche il suo significato semantico e altre proprietà rilevanti.
È grazie a queste rappresentazioni numeriche che il testo diventa “leggibile” dal modello, il quale manipolerà poi i numeri anziché le parole.
5. Contesto iniziale
Nella fase di analisi del testo, ChatGPT può anche considerare:
Istruzioni extra (metadati o impostazioni dell’utente), come richieste di stile, lunghezza preferita delle risposte o livello di profondità desiderato.
Contesto di conversazione (nei modelli basati su un thread di dialogo), per comprendere a quali precedenti messaggi l’utente si sta riferendo.
Pur non modificando la struttura base di tokenizzazione, questi elementi aggiuntivi indirizzano il modello verso una comprensione più accurata della richiesta, garantendo che ciò che verrà elaborato successivamente sia contestualizzato nel modo giusto.
6. Obiettivi dell’analisi del testo di Input
Riassumendo, lo scopo di questa prima fase è:
Convertire il testo in forma numerica (indispensabile per la manipolazione interna),
Mantenere l’integrità semantica (assicurarsi che il significato di ciò che l’utente ha scritto non venga perso o distorto),
Uniformare la struttura (ripulendo e normalizzando il testo), così da creare la base più solida possibile per l’elaborazione successiva.
Conclusione del Capitolo 1
L’analisi del testo di input rappresenta il punto di partenza imprescindibile: da come il messaggio viene processato e tradotto in numeri dipende la precisione con cui ChatGPT potrà cogliere il significato della richiesta. Nei prossimi capitoli esploreremo i passaggi successivi di questa catena, scoprendo come il modello “pensa” e produce la risposta una volta completata l’analisi iniziale.
Capitolo 2: Elaborazione attraverso l’Architettura Transformer
Dopo aver completato l’analisi e la conversione in token del testo di input (Capitolo 1), ChatGPT passa alla fase cruciale di elaborazione.
È qui che entra in gioco la struttura Transformer, il cuore pulsante del modello che consente di comprendere e generare testo in maniera sofisticata. In questo capitolo esploreremo come funziona il Transformer e quali sono i principali componenti e meccanismi che lo caratterizzano.
1. Panoramica dell’Architettura Transformer
Cos’è un Transformer?
Il Transformer è un’architettura di reti neurali basata principalmente sul meccanismo di attenzione (attention). È stato introdotto per superare alcune limitazioni dei modelli precedenti (ad esempio, le reti ricorrenti), consentendo di gestire in modo più efficiente il contesto di frasi o documenti lunghi.
L’architettura Transformer “classica” è composta da un Encoder (che elabora l’input) e da un Decoder (che genera l’output).
In ChatGPT, la parte chiave è un blocco di Decoder autoregressivi, specializzati nella generazione dei token uno dopo l’altro.
2. Meccanismo di Self-Attention
Il concetto di self-attention è ciò che rende il Transformer particolarmente efficace nel cogliere le relazioni tra le parole (o token) in una sequenza.
Che cos’è la Self-Attention?
È un meccanismo che permette a ogni token di “prestare attenzione” a tutti gli altri token della sequenza per capire come si relazionano tra loro.
Vantaggi rispetto a modelli precedenti:
Non è necessario un’elaborazione sequenziale (come avviene nelle reti ricorrenti).
La comprensione del contesto avviene in parallelo, permettendo una maggiore efficienza.
3. Mascheramento (Masking)
Per generare testo, ChatGPT utilizza un metodo chiamato autogressione, prevedendo un token alla volta. Ma come fa a “non sbirciare” i token futuri? Qui entra in gioco il mascheramento.
Scopo del Mascheramento:
Evitare che il modello veda token che non dovrebbe ancora “conoscere” (per mantenere la coerenza nel generare passo dopo passo).
Funzionamento:
Viene creata una sorta di “maschera” che oscura o attribuisce punteggi nulli ai token futuri, costringendo il modello a basarsi solo sui token passati e su quelli presenti.
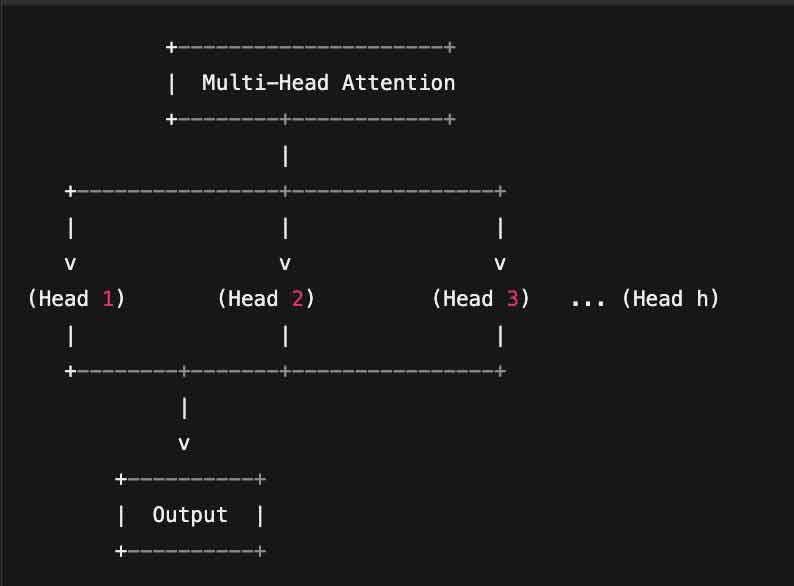
4. Multi-Head Attention
La Multi-Head Attention è un ulteriore perfezionamento della self-attention.
Invece di un singolo meccanismo di attenzione, se ne creano più “teste” (heads), ognuna specializzata a catturare differenti tipi di relazioni tra token.
Heads:
Ciascuna testa si concentra su diversi aspetti: sintassi, semantica, relazioni a breve o lungo raggio, ecc.
Aggregazione Finale:
I risultati di ogni testa vengono poi combinati, migliorando la ricchezza della rappresentazione del contesto.
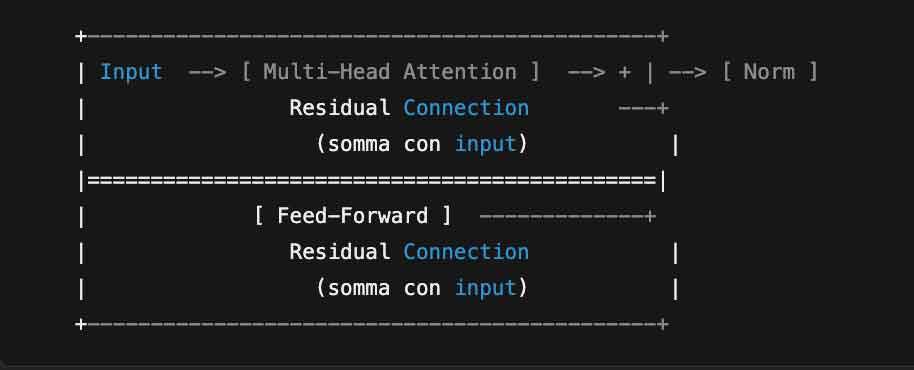
5. Feed-Forward e Residual Connections
Dopo la self-attention (o multi-head attention), i token passano attraverso strati chiamati Feed-Forward Network (FFN). Inoltre, i Transformer sfruttano le Residual Connections, ossia connessioni che aggirano alcuni strati, per aiutare la rete a propagare il gradiente e migliorare la stabilità dell’apprendimento.
Feed-Forward Network:
Una serie di livelli densi (fully connected) che elaborano i token uno alla volta, trasformandoli ulteriormente.
Residual Connections:
Consistono nel sommare l’input originale di uno strato all’output di quello stesso strato.
Aiutano a preservare l’informazione e a facilitare la retropropagazione del gradiente, riducendo il rischio di degradazione del segnale all’aumentare della profondità.
Lo schema mostra come, dopo ogni blocco di elaborazione (multi-head attention o feed-forward), ci sia un collegamento “residuale” che somma input e output, stabilizzando l’apprendimento.
6. Output del Decoder
Infine, ChatGPT produce l’output di ogni strato Transformer, rappresentato da vettori che contengono la comprensione del token in relazione ai token precedenti. Nella generazione:
Viene scelto il token successivo (tra quelli nel vocabolario) sulla base delle probabilità stimate.
Questo token si aggiunge alla sequenza, e il processo si ripete fino al completamento della risposta o al raggiungimento di un limite di lunghezza.
Conclusione del Capitolo 2 La potenza di ChatGPT risiede nell’architettura Transformer, che grazie alla self-attention, alla multi-head attention e alle feed-forward networks riesce a comprendere e a generare testo in modo coerente, tenendo conto delle relazioni a breve e lungo raggio tra le parole. Nel prossimo capitolo vedremo come queste rappresentazioni si combinano con le tecniche di generazione e di controllo di coerenza per produrre risposte articolate e pertinenti.
Capitolo 3: Generazione della Risposta
Dopo l’elaborazione del testo attraverso l’architettura Transformer (Capitolo 2), si giunge al momento decisivo: la generazione della risposta. Questa fase trasforma la comprensione interna del modello in un testo coerente e progressivo, un token alla volta.
Nel dettaglio, la generazione avviene grazie a un meccanismo autoregressivo, in cui ChatGPT utilizza ciò che ha già elaborato per prevedere il token successivo.
1. Predizione dei Token Successivi
In un modello come ChatGPT, la generazione è un processo iterativo chiamato autogressione. A ogni passo, il sistema:
Osserva la sequenza corrente: Includendo i token dell’input e quelli eventualmente già generati in precedenza.
Calcola la probabilità di ciascun token possibile: Grazie ai pesi e alle strutture interne (multi-head attention, feed-forward, ecc.), il modello stima la probabilità di generare ogni token presente nel suo vasto vocabolario.
Seleziona il token con la probabilità più alta o in base a un criterio di campionamento (si veda la sezione successiva).
Aggiunge il token generato alla sequenza, che diventa così più lunga di un’unità.
Ripete il procedimento finché non viene raggiunto un limite (ad esempio, un numero massimo di token) o una condizione di arresto (come l’emissione di un token “fine frase”).
Da un punto di vista intuitivo, è come se ChatGPT completasse una frase parola dopo parola, basandosi sull’intero contesto già prodotto.
2. Gestione della Coerenza
Per evitare di generare risposte prive di logica o di contraddirsi a metà discorso, ChatGPT fa leva principalmente sul meccanismo di self-attention (descritto nel capitolo precedente) che gli consente di:
Recuperare il contesto: Ogni token può “guardare” i precedenti, rilevando la coerenza sintattica e semantica.
Regolare lo stile: Se una richiesta dell’utente specifica un certo tono o un livello di profondità, tale informazione è memorizzata e presa in considerazione durante la generazione dei token successivi.
Mantenere la linearità del discorso: Grazie all’autogressione, il modello non salta parti importanti e procede “a cascata”, garantendo un collegamento logico tra le frasi.
Inoltre, la conversazione contestuale (dove supportata) consente a ChatGPT di riferirsi a elementi menzionati in precedenza, evitando ripetizioni inutili o incongruenze con le parti già espresse.
3. Parametri di Generazione (Temperature, Top-k, Top-p)
Una volta calcolate le probabilità di ciascun token possibile, ci sono diversi modi per decidere quale token inserire effettivamente nella risposta.
Per controllare creatività, coerenza e accuratezza, ChatGPT offre una serie di parametri di generazione:
Temperature
Regola la “creatività” del modello: se la temperature è alta, il modello è più propenso a scegliere token meno probabili, rendendo le risposte più originali ma anche potenzialmente meno coerenti.
Se la temperature è bassa (prossima a zero), il modello sceglie quasi sempre i token più probabili, producendo risposte più prevedibili e precise.
Top-k
Limita la scelta dei token solo ai “k” più probabili.
Riducendo k, si elimina la coda di token con probabilità molto bassa, restringendo la possibile varietà di risposte.
Top-p (o nucleo di probabilità)
Simile a Top-k, ma al posto di un numero fisso di token, si impone una soglia di probabilità cumulativa “p” (ad esempio 0.9).
Vengono considerati solo i token che, sommando le rispettive probabilità, non superano quella soglia.
Consente al modello di regolare dinamicamente il numero di token candidati, in base al contesto.
Scegliere i valori giusti per questi parametri aiuta a bilanciare originalità e affidabilità della risposta. Con valori “ristretti” (temperature bassa, k e p molto piccole) si ottiene un testo più prevedibile ma molto coerente; con valori più ampi, si ottiene una varietà maggiore ma si rischiano deviazioni o imprecisioni.
4. Convergenza e Arresto della Generazione
La generazione prosegue finché non viene raggiunto un criterio di arresto, che può essere:
Lunghezza massima: Se l’utente non specifica un limite, spesso esiste un massimo definito dal sistema, superato il quale la generazione viene interrotta.
Token di fine sequenza: In alcuni casi, il modello può inserire un token speciale che indica la conclusione di una risposta.
Euristiche o vincoli di contesto: Se, ad esempio, il contesto suggerisce una risposta breve o se la domanda è stata soddisfatta in anticipo, il sistema può terminare spontaneamente.
Durante la generazione, il modello monitora costantemente la sintesi tra coerenza e concisione, al fine di non dilungarsi inutilmente o generare risposte interrotte a metà.
5. Rilevanza e Filtro di Contenuto
Un aspetto ulteriore, che spesso coincide con la produzione della risposta, è la verifica di aderenza alle politiche di contenuto e la coerenza tematica. Nel caso di ChatGPT, se l’utente fa richieste inopportune o in violazione di norme, il modello può:
Omettere o riformulare parti della risposta,
Rifiutare esplicitamente di fornire informazioni,
Fornire avvertenze o linee guida.
Questo filtro avviene grazie a un insieme di regole e istruzioni apprese o configurate durante la fase di addestramento o nel contesto di sicurezza dell’applicazione.
6. Rifinitura Finale
Nelle implementazioni pratiche, può esistere una fase di post-elaborazione per rendere la risposta più naturale:
Correzione di eventuali doppi spazi, punteggiatura e frasi tronche,
Formattazione in base alle richieste (esempio: elenco puntato, stile formale, ecc.),
Aggiunta di frasi di accompagnamento, qualora servissero chiarimenti o note preliminari.
Tuttavia, il cuore della generazione risiede nel passaggio già descritto: la previsione iterativa dei token, regolata da parametri che definiscono come il modello equilibrerà coerenza e varietà espressiva.
Conclusione del Capitolo 3 La generazione della risposta è il momento in cui l’architettura trasforma la comprensione interna (costruita grazie al meccanismo di self-attention e al mascheramento) in testo concreto, un token alla volta. Grazie ai parametri di sampling (temperature, top-k, top-p) e all’uso delle informazioni contestuali, ChatGPT riesce a produrre risposte coerenti e adeguate alle richieste dell’utente. Nel prossimo capitolo si vedrà come l’uscita finale venga controllata e rifinita per garantire qualità, pertinenza e rispetto delle linee guida di sicurezza e contenuto.
Capitolo 4: Rifinitura con Istruzioni e Contesto
Una volta generata la sequenza di risposta (Capitolo 3), ChatGPT può ulteriormente perfezionare il testo in base alle istruzioni dell’utente e al contesto della conversazione o dell’applicazione in cui è inserito. Questa rifinitura consiste nell’armonizzare il contenuto con eventuali linee guida, stili richiesti e informazioni precedentemente fornite. Vediamo in che modo questa fase si articola:
1. Interpretazione delle Istruzioni
Quando l’utente fornisce comandi o preferenze specifiche, queste istruzioni possono influenzare il tono, la forma e la struttura della risposta. Alcuni esempi di istruzioni sono:
Stile di scrittura:
“Sii formale”, “Usa un linguaggio semplice”, “Scrivi in prima persona”
Queste indicazioni guidano il modello a modulare la risposta scegliendo frasi più raffinate o più colloquiali.
Lunghezza desiderata:
“Fornisci una risposta breve”, “Scrivi un riassunto in un singolo paragrafo”
ChatGPT cerca di rispettare i limiti di battute o di paragrafi indicati, pur mantenendo la coerenza di contenuto.
Obiettivo e Contenuto Specifico:
“Cita fonti”, “Includi esempi pratici”, “Non utilizzare termini tecnici”
Questi vincoli suggeriscono di arricchire (o semplificare) la risposta in funzione delle esigenze dell’utente.
L’elaborazione di tali istruzioni è possibile perché il modello integra queste richieste nel meccanismo di attenzione e di generazione, valutando come applicarle a ogni token prodotto durante la composizione.
2. Contestualizzazione con la Conversazione Precedente
In scenari conversazionali, ChatGPT tiene traccia del thread di dialogo, ovvero di tutti i messaggi precedenti, per:
Evitare ripetizioni inutili: Se una domanda è stata già affrontata, il modello tenterà di riassumere o richiamare concetti anziché ripetere le stesse frasi.
Approfondire informazioni: Se l’utente chiede un dettaglio aggiuntivo su un argomento già discusso, ChatGPT riprende i riferimenti forniti in precedenza, mantenendo la continuità.
Regolare la coerenza logica: Le affermazioni fatte in un turno della conversazione vengono considerate come contesto per le turnazioni successive, evitando incongruenze (ad esempio contraddirsi rispetto a un punto già espresso).
3. Filtri e Linee Guida
Oltre alle istruzioni specifiche dell’utente, ci sono linee guida di sistema più ampie (o “policy”) che ChatGPT deve rispettare. Queste possono riguardare:
Sicurezza e contenuto sensibile:
Rifiutare o filtrare risposte legate a contenuti illegali, dannosi o proibiti.
Fornire avvertimenti quando si trattano argomenti delicati.
Tutela dei dati:
Evitare di divulgare informazioni sensibili.
Non memorizzare dettagli privati della conversazione oltre il tempo strettamente necessario per l’elaborazione.
Esigenze editoriali o aziendali:
Rispetto dello stile aziendale (ad esempio, lessico istituzionale, formattazione standard).
Linee guida su come e quando usare esempi o riferimenti esterni.
Le risposte generate, prima di essere fornite all’utente, possono quindi passare attraverso un filtro di validazione che ne verifica la conformità alle policy. Se la risposta viola qualche regola, viene aggiustata o, in casi estremi, bloccata.
4. Gestione di Prompt Ingegnerizzati (Prompt Engineering)
In certi contesti, gli sviluppatori o i tecnici che integrano ChatGPT nelle loro applicazioni possono fornire “istruzioni precompilate” chiamate prompt ingegnerizzati. Questi prompt:
Definiscono il personaggio o il ruolo: “Rispondi come se fossi un insegnante di matematica per bambini delle elementari.”
Strutturano la risposta: “Fornisci la soluzione a un problema in 5 passaggi logici, numerandoli chiaramente.”
Dettano comportamenti di fallback: “Se non conosci la risposta, sii onesto e suggerisci di consultare fonti esterne.”
Questa tecnica permette di orientare il modello verso determinati stili, linguaggi o finalità, senza che l’utente debba formulare sempre le istruzioni di base.
5. Aggiunta di Dettagli e Coesione
In fase di rifinitura, ChatGPT può anche:
Ampliare o abbreviare alcune parti della risposta, se emerge che il livello di dettaglio non è adeguato alle istruzioni date.
Introdurre esempi o analogie per chiarire un concetto, specialmente se l’utente richiede ulteriore chiarezza.
Riorganizzare il testo in paragrafi, elenchi o sezioni più leggibili, in linea con le regole di formattazione suggerite.
Spesso questi accorgimenti migliorano la coesione e la fruibilità del contenuto, aumentandone il valore didattico o informativo.
6. Conseguenze sul Risultato Finale
La rifinitura con istruzioni e contesto assicura che la risposta finale non sia solo frutto di un calcolo probabilistico, ma anche di un’interpretazione delle richieste e delle politiche in atto. Questo comporta:
Maggiore pertinenza: La risposta risulta più centrata su ciò che l’utente desidera, con un tono e uno stile adeguati.
Riduzione delle ambiguità: I riferimenti e i dettagli sono contestualizzati alla specifica situazione della conversazione, evitando risposte generiche o fuori tema.
Conformità alle linee guida: Il testo finale rispetta vincoli etici, legali o editoriali, creando maggiore affidabilità e sicurezza.
Conclusione del Capitolo 4 La fase di rifinitura incorpora una serie di passaggi cruciali: dall’interpretazione delle istruzioni dell’utente, alla gestione del contesto precedente, all’applicazione di filtri e policy. Tutto ciò garantisce che la risposta di ChatGPT non sia solo formalmente corretta, ma anche adattata alle esigenze specifiche di chi fa la domanda e in linea con le regole e gli standard di sicurezza. Nel capitolo successivo ci concentreremo sulla fase conclusiva, dove la risposta, ormai completa, viene finalizzata e presentata all’utente.
Capitolo 5: Controllo Qualità e Finalizzazione
Una volta completate le fasi di generazione (Capitolo 3) e rifinitura (Capitolo 4), la risposta è quasi pronta per essere consegnata all’utente.
Prima, però, c’è un’ultima fase di controllo qualità e di finalizzazione, in cui ChatGPT effettua verifiche aggiuntive per garantire che il testo soddisfi gli standard di coerenza, di adeguatezza e di rispetto delle linee guida. Vediamo in cosa consiste questo passaggio conclusivo.
1. Verifica di Coerenza e Completezza
In questo stadio, il modello (o una procedura interna collegata) può effettuare una sorta di ricontrollo della risposta generata. Gli obiettivi principali sono:
Individuare incongruenze: Se la risposta contraddice affermazioni precedenti o fornisce informazioni non allineate al contesto, il sistema tenta di armonizzare il testo.
Valutare l’esaustività: Viene verificato se la domanda dell’utente ha ricevuto una trattazione completa o se esistono punti rimasti in sospeso.
Controllare la chiarezza: Talvolta, alcune frasi possono risultare ambigue o poco chiare; se il modello lo rileva, può provare a semplificarle o espanderle.
Anche se ChatGPT, in fase di generazione, gestisce buona parte di questi aspetti, questa verifica finale offre un’ulteriore opportunità di pulizia e rafforzamento del testo.
2. Confronto con le Policy di Contenuto
La risposta elaborata viene quindi confrontata con le regole di sistema o dell’organizzazione che gestisce ChatGPT. Ciò include:
Verifica di aderenza: Se ci sono disposizioni che vietano certi argomenti o toni, questa fase interviene per segnalare anomalie (ad esempio contenuti offensivi, illegali o sensibili).
Filtraggio o Censura parziale: Nel caso in cui la risposta violi delle linee guida, può essere applicato un filtro per rimuovere o riformulare le sezioni non conformi.
Rifiuto: Se il testo genera un contenuto estremamente inappropriato o fuori policy, il sistema potrebbe decidere di non fornire alcuna risposta o di restare sul vago, motivando la limitazione.
3. Rifinitura Formale e Stilistica
Oltre all’adeguatezza contenutistica, è importante che il testo finale sia ben formattato e stilisticamente coerente. In questa sottosezione, ChatGPT può:
Correggere eventuali errori formali: Ortografia, punteggiatura, utilizzo dei tempi verbali, ecc.
Migliorare la leggibilità: Dividere la risposta in paragrafi, elenchi puntati o titoli, se l’utente lo richiede o se risulta utile a chiarire i contenuti.
Uniformare lo stile: Se l’utente ha specificato preferenze (ad esempio, “in forma di lettera” o “con un linguaggio professionale”), il testo viene ulteriormente adeguato a tali linee.
4. Eventuali Disclaimer o Note di Chiusura
Per argomenti complessi o sensibili, ChatGPT può aggiungere note di cautela o disclaimer. Queste indicazioni servono a:
Chiarire i limiti della risposta (ad esempio, “Queste informazioni non sostituiscono il parere di un professionista”).
Invitare alla verifica di fonti esterne, specialmente per questioni di natura tecnica, medica o legale.
Ricordare la natura statistica del modello, che può commettere errori di interpretazione o di calcolo.
5. Presentazione Finale della Risposta
Conclusi i controlli di coerenza, policy e stile, la risposta viene finalmente presentata all’utente. Da questo punto in poi, entra in gioco l’interazione vera e propria, in cui:
L’utente può leggere e valutare la risposta fornita.
Se la ritiene incompleta o insoddisfacente, può porre ulteriori domande o chiedere chiarimenti.
ChatGPT, eventualmente, rilancia il ciclo di analisi, generazione e rifinitura per rispondere ai nuovi spunti.
6. Importanza del Controllo Qualità e della Finalizzazione
Perché è così cruciale questa fase finale?
Affidabilità: Una risposta che supera controlli multipli è meno soggetta a contenere errori o contraddizioni.
Sicurezza: Risponde alle esigenze di contenimento di contenuti illeciti, offensivi o non conformi alle norme vigenti.
Professionalità: Un testo ben scritto, coerente e rifinito riflette credibilità e cura nei confronti dell’utente.
Conclusione del Capitolo 5 Il Controllo Qualità e la Finalizzazione rappresentano lo “scudo” finale che separa la bozza generata dalla risposta definitiva. Attraverso meccanismi di verifica formale e contenutistica, ChatGPT garantisce che ogni risposta risulti coerente, aderente alle policy e adeguata al contesto di utilizzo. Con questo passaggio, si chiude l’intero processo: dal momento in cui l’utente invia la domanda, fino alla consegna di una risposta accurata e ben calibrata sulle sue esigenze.
Capitolo 6: Rilascio della Risposta all’Utente
Completate tutte le fasi precedenti — dalla comprensione e analisi dell’input, passando per l’elaborazione del testo, la generazione, la rifinitura e il controllo qualità — si giunge al momento in cui ChatGPT fornisce la risposta definitiva a chi l’ha richiesta.
Anche se a livello operativo può sembrare solo un passaggio “formale”, in realtà il rilascio della risposta racchiude in sé alcune considerazioni importanti sul modo in cui l’utente riceve, valuta e utilizza le informazioni.
1. Consegna del Testo Generato
Trasmissione verso l’utente:
Una volta conclusa la fase di finalizzazione, la risposta viene consegnata all’interfaccia (ad esempio, una chat web o un’API) che l’utente sta utilizzando.
A livello tecnico, ciò può avvenire in un singolo blocco di testo oppure in forma “streaming” (token dopo token), a seconda della configurazione dell’applicazione.
Formattazione finale:
Se richiesto, la risposta può essere presentata con elementi di formattazione (paragrafi, grassetti, titoli) per renderla più leggibile.
In caso di integrazioni specifiche (come tabelle o codice), la risposta include la sintassi adatta.
2. Valutazione del Risultato
Dopo aver ricevuto il testo, l’utente può effettuare la propria valutazione:
Pertinenza: La risposta risponde davvero alla domanda posta?
Completezza: Copre tutti gli aspetti richiesti o ci sono lacune da colmare?
Chiarezza e Stile: È formulata in modo semplice o specialistico a sufficienza? Rispetta le preferenze di linguaggio?
Nel caso in cui alcuni punti non siano stati affrontati o risultino poco chiari, l’utente può formulare una domanda di follow-up, dando il via a un nuovo ciclo di elaborazione.
3. Interazione Successiva e Aggiornamenti
Nonostante ChatGPT abbia “memoria” del contesto in una sessione di conversazione, è importante notare che:
Nessun apprendimento diretto: A differenza di un utente umano, il modello non apprende permanentemente dalle singole interazioni. Ogni conversazione non si traduce in un addestramento diretto o in una modifica stabile del modello.
Privacy e Sicurezza: I dati della conversazione non vengono memorizzati a lungo termine dal modello (in base alle politiche del fornitore). Ciò consente di salvaguardare le informazioni sensibili fornite dall’utente.
Feedback e miglioramenti futuri: Se l’applicazione prevede meccanismi di feedback (pulsanti “Utile”/“Non utile” o revisioni manuali), tali valutazioni possono confluire in aggiornamenti successivi del sistema, ma non in tempo reale.
4. Possibili Limitazioni
Nel rilasciare la risposta, è essenziale considerare che:
Il modello può commettere errori: Le reti neurali di grandi dimensioni, pur avendo enormi capacità di calcolo, non garantiscono sempre l’accuratezza assoluta.
Le informazioni possono essere incomplete o datate: Soprattutto se si fa riferimento a dati, eventi o ricerche più recenti rispetto all’epoca dell’addestramento.
Il contesto influisce sulla qualità: Se la domanda non è chiara o non fornisce abbastanza informazioni, la risposta potrebbe risultare vaga. È sempre consigliabile fornire maggiori dettagli per una maggiore precisione.
5. Importanza della Chiusura del Ciclo
Il rilascio della risposta, unito alla possibilità di interazione iterativa (domande di chiarimento, correzioni di rotta, specifiche aggiuntive), fa di ChatGPT uno strumento collaborativo. L’utente, di fatto, non riceve solo un testo statico, ma può coinvolgere il modello in uno scambio continuo per:
Affinare la conoscenza: Attraverso ulteriori prompt e chiarimenti.
Personalizzare l’output: Cambiando istruzioni e parametri di generazione (ad esempio, riducendo o alzando la temperatura).
Integrare altre fonti: Il testo di ChatGPT può essere confrontato o arricchito con documenti esterni e pareri di esperti.
Conclusione del Capitolo 6 La fase di rilascio della risposta chiude il ciclo di elaborazione di ChatGPT. Se ogni passaggio precedente — dall’analisi iniziale alla rifinitura — è stato eseguito correttamente, l’utente riceverà una risposta coerente, pertinente e (quando possibile) accurata. La vera forza di un sistema conversazionale, tuttavia, risiede nella possibilità di dialogo continuo, che permette all’utente di proseguire con domande di approfondimento o correzioni, in un percorso iterativo di chiarificazione e apprendimento.
Tutto sull’intelligenza artificiale nel settore AEC: progettazione, BIM, cantiere, manutenzione e gestione tecnica. Scopri come l’AI sta cambiando il lavoro dei professionisti delle costruzioni.
IMREADY Srl tratterà i dati personali da te forniti in questo form nel rispetto del GDPR.
Inviando questo form acconsenti al trattamento dei dati personali necessario all'iscrizione all'Area Riservata di questo sito e all'eventuale consultazione di sezioni riservate del sito.
Inviando questo form acconsenti anche al trattamento dei dati personali necessario all'iscrizione alla nostra mailing list, con l'intenzione di ricevere comunicazioni informative e/o commerciali da parte nostra.
Puoi esercitare i tuoi diritti relativi al trattamento dei dati personali inviando una richiesta a info@ingenio-web.it, che verrà gestita senza ingiustificato ritardo.
Potrai modificare le impostazioni di ricezione delle comunicazioni e/o annullare l'iscrizione alla mailing list tramite appositi link in fondo alle comunicazioni.